Testbed design change and development
For posterity: http://widget.chipin.com/widget/id/d6208430185ee1a5
Please see clarification.
The next goal for the testing system (centered at testing.drupal.org) is to test Drupal 6, Drupal 6 contrib, and eventually Drupal 7 contrib. This will require:
- Additional testing computers to be added to the current fleet of 4-6 servers which handles the Drupal 7 core load
- Re-architecting the automated testing system as described below
- The addition of new features described in my previous post, The Future of Automated Patch Testing
In order for me to be able to devote significant resources in the short term to get this completed it would very helpful to have funding. I would like to raise $3,000 for the development of the new system.
Before describing the details of the new system, lets look at how the current system works.
Current system
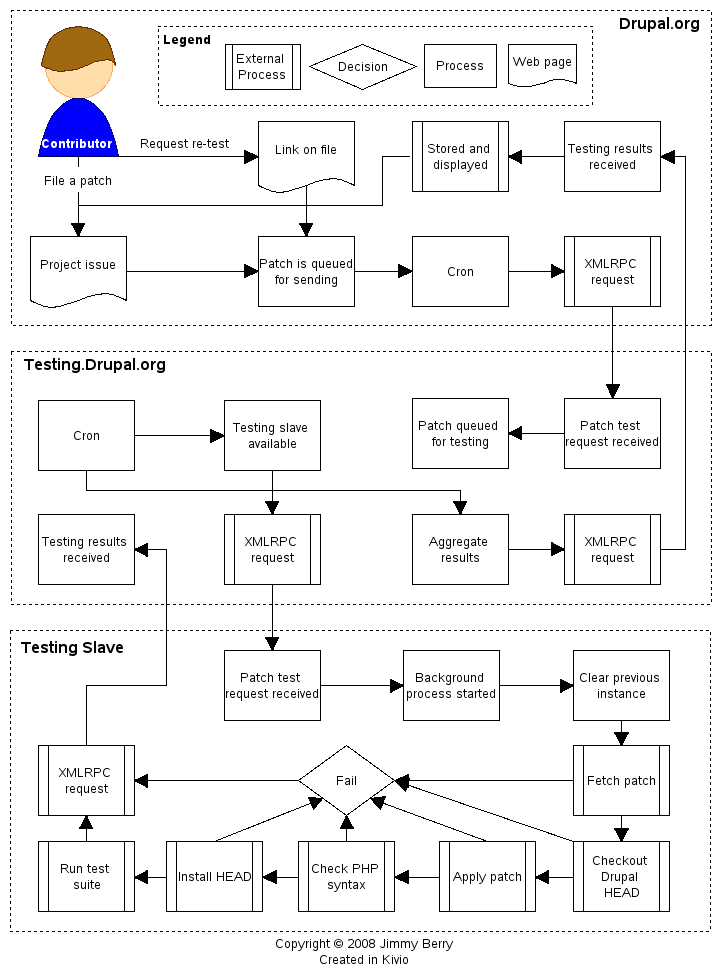
The automated testing system has three stages, or sections, to it. The sections are illustrated in the figure to the right, but I’ll give an overview of what they do.
- The project server that manages all the issues related to projects. - drupal.org
- The testing master server which distributes the testing load and aggregates the results to the appropriate project server. - http:testing.drupal.org
- The testing server that performs the patch review and reports back to the master server. - network of servers
New architecture
The automated testing system is classified as a push architecture. That means that the testing master server pushes (ie. sends) patches to each of the testing servers. The new architecture will be based on a client/server model where the test client pull (ie. request) patches to test from the server.
In addition to changing the basic architecture of the system the large feature list will also be implemented. After all is said and done the new system will provide a more powerful tool to the Drupal community.
Reasoning
The motivation for making the change is due to the difficulties we have run into while maintaining the system for the last few weeks.
- Adding a testing server requires the entire system to be put on "hold".
- There is not an automated way to confirm that a testing server is functioning properly.
- When a testing server becomes "messed up" or "un-reachable" the system does not automatically react.
- Server administrators cannot simply remove their server from the fleet; they must first inform us that they are doing so.
All this manual intervention adds up to a large amount of time that Chad “hunmonk” Phillips and I have to spend to keep the system running smoothly. As we look to add more servers our time commitment will increase to the point where it is not feasible to maintain the system, thus the changes are required.